Sentiment Analysis of Long-term of Social Data during the COVID-19 Pandemic
Directed Research Project
Spring 2021
PROJECT DETAILS
Social Network Sentimental Analysis is a directed research project which focus on the sentiment of long-term social media content during the covid-19 pandemic. The project was directed under Prof. Hailu Xu at CSU, Long Beach.
ACHIEVEMENT
This research paper is accepted for publication in the Springer Nature - Research Book Series: Transactions on Computational Science & Computational Intelligence. It is scheduled to be published soon after the 22nd International Conference on Internet Computing & IoT (ICOMP'21), which will take place in July 26-29, 2021, USA.
PAPER ID #: ICM4216
TITLE OF PAPER/ARTICLE: Sentiment Analysis of Long-term Social Data during the COVID-19 Pandemic Sophanna Ek, Marco Curci, Xiaokun Yang, Beiyu Lin, Hailu Xu
Overview
The global outbreak of COVID-19 pandemic has changed and disrupted the human's lives in the past year. By March 2020, the deadly virus has been spread to 223 countries, and reached to 119 million cases and more than 2 million deaths. Despite the spreading of real virus worldwie, social medias, plays an important key as means to recieve and post news information in the daily updates.
Social networks show strong emotional reactions towards the pandemic in the past year. During the pandemic, a large number of social posts related to rumors, hate speech, racist conspiracy, and negative sentiments had quickly proliferated on the social networks. In this research work, we've studied the sentiment analysis specifically on Twitter social network data. For a full research work, please see here.
IMPLEMENTATION
- Twitter API, TextBlob, and Panda Libaries
FEATURES
- Data Collection and Processing
- Analysis Methods
- Sentiment Analysis
- Tweet Gender Classification using supervised machine learning algorithm
Research Work Pipeline
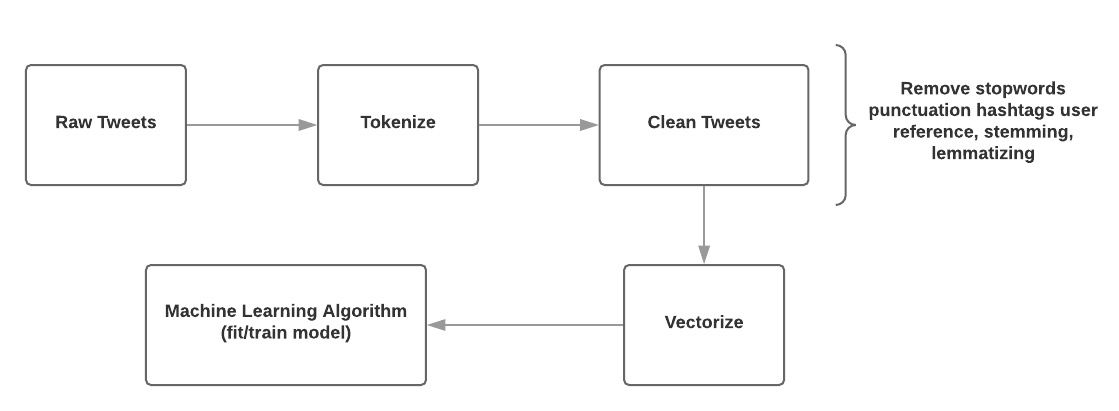
Data Collection
The data collection was done by using the Tweepy API with the access token from Twitter. The tweets selection was filtered by using the relevant keywords including "covid-19" and "vaccine" or any hashtags such as "#covid-19" or "#coronavirus". The data was collected on weekly basis from the 1st - 7th, 8th -14th, 15th - 21st and 22nd - 28th/30th periods for 12 months. The volume of the weekly collection was varied between 25,000 to 35,000. The total collected tweets up to approximately 1,300,000 tweets from February 2020 to February 2021.
Data Processing
We performed the data preprocessing on each data instance before performing the data analysis. All collected tweets had been preprocessed in the following order:
- Each tweet content is extracted by removing url link, user references, punctuations and hashtags symbol
- Then extracted text was then tokenized and have common English stop words removed.
- The cleaned text was then applied the stemming process using Porter Stemmer to remove the morphological affixes from words and leaves only the word stem for our analysis.
- The text was then applied the lemmatization to keep the word to its meaningful base form. We also use the stop words, Porter Stemmer, and Lemmatization from the NLTK Library (Natural Language Toolkit) in python for the data processing.
Analysis methods
- TF-IDF:
- Sentiment Analysis
TF-IDF method was used to find more important topics from the collected tweet data using the TF-IDF score. Instead of giving every word with equal importance, TF-IDF gives more importance to the words that occur more frequently in one document and less frequently in other documents. TF-IDF score is determined by conducting the word’s term frequency and its inverse document frequency. TfidfVectorizer in sklearn python library was used to learn the pre-processed tweet data and score each term appear in the tweet corpus.
The sentiment analysis is performed on the same pre-processed tweet dataset. TextBlob [5] is a python library that can perform the common natural language process tasks such as sentiment analysis, classification, noun phrase extraction, and more. It assigns individual scores to all the words, then takes an average of all the sentiments to calculate the final sentiment. It takes the pre-processed tweet content and gives the polarity score which is used to determine the sentiment of the tweet data. The score is range from -1 to 1. The content is said to be negative if the polarity score is less than 0, positive if it is greater than 0, and neutral if it is equal to 0
Analysis Result
we perform the sentiment analysis with the collected data and investigate the sentiment patterns of content-level, political and social cognitive attributes. We provide perspectives on social data in three categories: vaccine-related, politic-related, and economic-related. Besides, we explore the differences of views among gender effects.
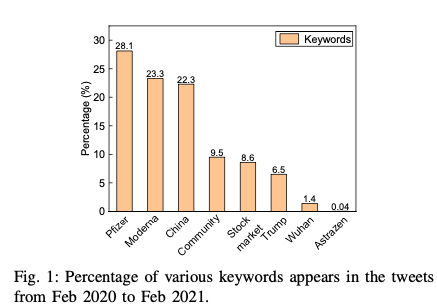
- Using the TF-IDF method to analyze the frequency of various keywords among all the collected tweets.
The top 6 keywords are shown in the figure 1 below.
-
To understand the sentiment tweets, we study three key topics that refer to:
- economic during the pandemic,
- political discussion related to the U.S presidential election,
- the procedure of mRNA vaccines
The tweet is defined to be vaccine relevant if it contains any words of the name of vaccine company, and keywords such as "vaccine", "vaccine distribution","mutation", "injection", "mRNA", etc. The economy revelvant tweet can be classified if it contains "job", "nasdaq","economy", "stock", "S&P500", "stimulus", and "opening". Tweets refer to politics can be identified if it contains ‘election’, ‘political’, ‘campaign’, ‘elected’, ‘politics’, and the name of candidates.
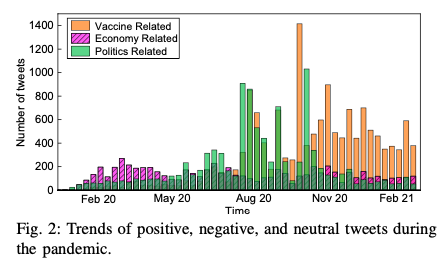
Next, we investigate the attitudes of users during the pandemic, where we separate the tweets into three categories according to Bayes classification: positive, negative, and neutral. Figure 2 displays the trends of three categories over a 12-month period, where each data point presents the topics within a single week.
-
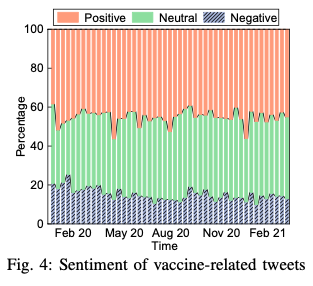
Figure 4 shows the distribution of negative, positive, and neutral tweets during the 12 months’ period of time. We can observe that the negative tweets have the highest volume at the beginning of the pandemic and decline with the time.
-
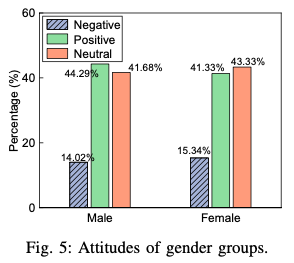
Next, we analyze the attitudes of users for tweets that relate to vaccine and genders. Demographic data such as gender and age are not available from the Twitter API due to the restriction of its users’ privacy rule, therefore we identify Twitter users’ gender by using the gender classifi- cation based on tweet content. The gender classification was trained with available training dataset on Kaggle [1] by using the multinomial Na ̈ıve Bayes classifier [21] in Sklearn library. To better train the classifier, only data with 99% gender- confidence were chosen to include in our data set.
Figure 5 shows the attitudes among different genders.
Conclusion
In this work, we conduct a long-term analysis of social posts that related to COVID-19 within 12 months. We analyze the collected social data in three categories: vaccines, politics, and economics and analyze the sentiment attitudes of tweets from various perspectives. Our analysis shows that negative tweets occupy an important position during the pandemic and decline with the development of vaccines. Besides, the evolution of various topics tightly follow the hot discussions on economics, politics, and vaccines.
Future Work
we will analyze the tweets by targeting on deeper and more comprehensive perspectives. We will continue to explore the variances among different topics and show the roles that genders feeds back at different stages of the ”infodemic”. Besides, we will characterize sentiment patterns to extend the understanding of the impacts of online social ”infodemic”.